Yesterday I made a mess
Normally when I write a blog post it's because I have exciting news to share. This time it's not a fun occasion because the only good news I have is that the bad news isn't permanent.
The bad news is that during some database maintenance yesterday (June 13th) I accidentally removed some of the data from users' encrypted drives. The good news is that these files were archived, not deleted, and that everything can be recovered.
Before I get into the details of why this happened I'd like to clarify which user data was archived and how to check if your account was one of those affected.
How to tell if you were affected
First off, everything is related to my actions administrating the database of CryptPad.fr. Users of other instances have nothing to worry about unless their administrator did the exact same thing as I did, which is unlikely.
Secondly, the issue is limited to shared folders and non-owned files contained within them. If you don't use shared folders you won't be affected.
Thirdly, as far as we can tell you need to have visited CryptPad.fr between May 28th and June 13th in order to have run some incorrect code.
Finally, nothing was archived unless it had not been active within the preceding 90 days. In the case of shared folders, this would mean any change to the content or structure of the shared folder, such as adding or removing a document or renaming or moving any of its contents. In the case of pads, if a user with the rights to edit the document loaded it without making any changes, that would classify it as active.
To summarise:
Some of your data could have been archived if you visited https://CryptPad.fr between May 28th and June 13th (2019) and have one or more shared folders in your CryptDrive which have not been modified within the last 90 days.
Checking if you were affected
It should be fairly easy to tell if your account was affected by opening your CryptDrive. Affected shared folders will be visible in the tree on the left of your drive because they'll have lost their titles, as highlighted in red below:
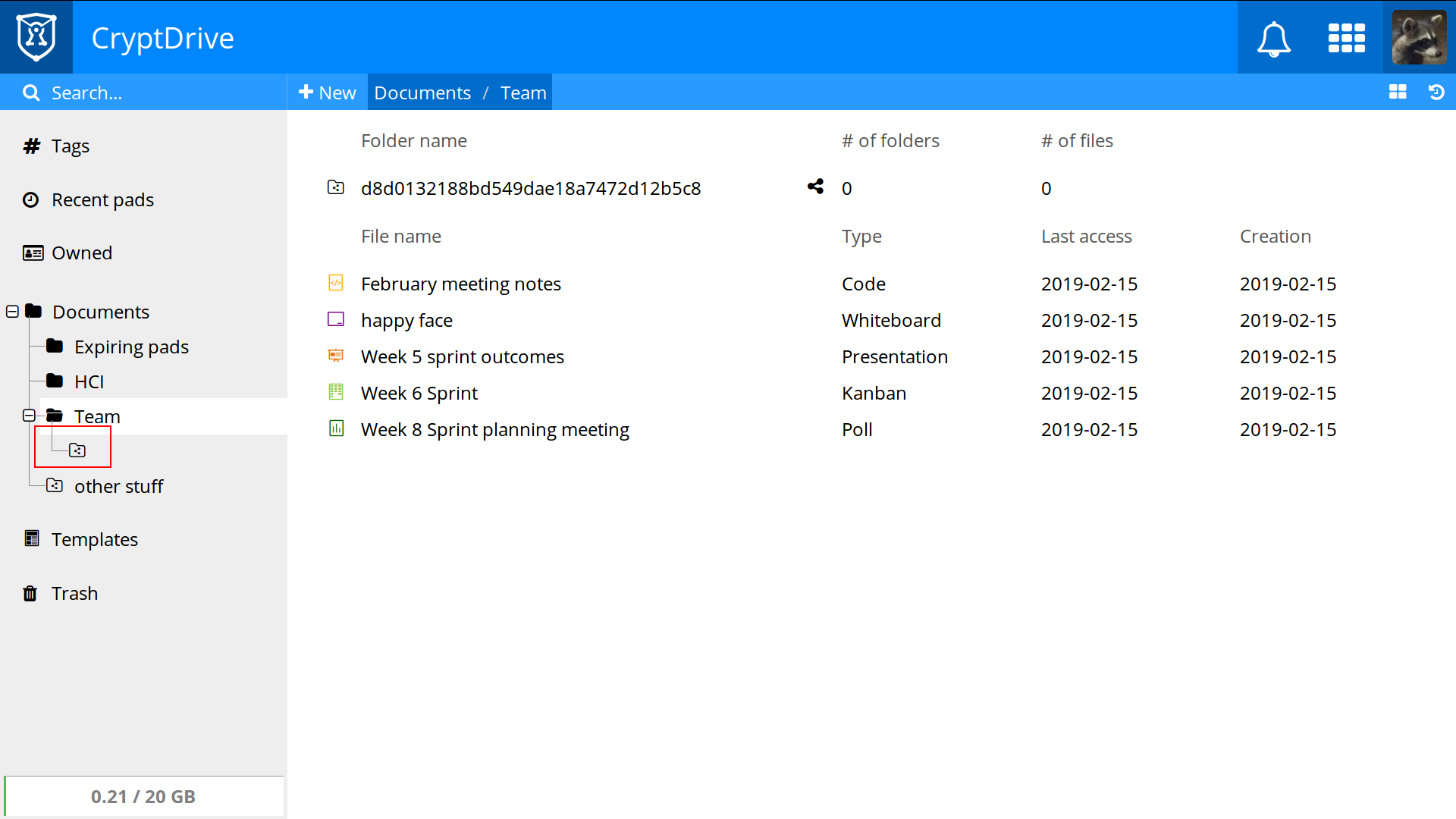
How we're going to handle this
As I said, none of the data was deleted, just archived. It's still on the same server that hosts the rest of our database, it's just been moved to a different location to make it inaccessible.
I've already restored all of those files which were archived except for 237 cases. Affected Users that visited CryptPad.fr between the removal and restoration of the data would have automatically created a new folder in the same location as the old one, and that complicates things for us. Since we don't know whether they might have decided to put new documents in that folder in the meantime, it's dangerous for us to overwrite the new data with the old.
It's going to take us a few days to figure out if we can use some fancier methodology to identify what data we can safely reinstate. In the meantime, we've already fixed the underlying issues that caused this data to be miscategorized, and developed some new tooling for safely diagnosing and restoring archived data.
Since we know that those affected by this error visited since our last release day and that they had content older than 90 days, we assume they're going to come back to the platform. If you do come back and see something resembling the image above, please do let us know by emailing us at contact@cryptpad.fr. We can manually restore any files that haven't already been restored.
I'm very sorry for any inconvenience this might have caused and I'm grateful that the damage wasn't worse. I'll take this as an opportunity to prove my commitment to protecting user data, whether it be from surveillance or from my own mistakes.
Post-mortem
With all the practical details addressed for those who only have the time to make sure their own data is safe, I'll go further into the specifics for anyone who might be interested.
The pinning race condition (May 28th)
On May 28th we released CryptPad Xenops. It introduced notifications for users through the use of something we've been calling "encrypted mailboxes". Each registered user now has a mailbox through which any other user can send messages, currently for friend requests, and soon for other features.
While we were implementing the function which loads new messages from this mailbox we introduced a bug which caused some other functions to be executed in the wrong order. I personally reviewed the code but didn't see the bug.
Registered users are able to send instructions to the server not to delete data that is relevant to them. We call this process "pinning" and it's done every time a user uses the service.
What should have happened is that users should have loaded their drive, then loaded their shared folders, then pinned all the contained files. Instead, they loaded their drive and then started loading their shared folders and started the pinning process in parallel. This caused what's called a race condition, which means that two things happen at the same time, and sometimes they happen in different orders.
Race conditions are especially annoying because sometimes they only occur under certain circumstances, so these bugs tend to slip past basic testing unless you already know what you're looking for. In our case, losing the race meant that files weren't pinned and consequently the server didn't have an accurate notion of which data was worth keeping.
Running out of space (June 3rd)
Several months ago a user contacted us saying that data had disappeared from their drive. This was quite scary from our perspective as for every user that contacts us about something we can generally assume that there are many more that had the same issue, but didn't say anything.
We spent several days debugging their problem and developing tools which would analyze the history of their drive without exposing any of their encrypted content to us. In the end, it turned out that the files didn't ever exist in their history, so it wasn't a matter of us losing that data. Nevertheless, the situation was stressful enough that we turned off all of our scripts for deleting inactive data until we could sort out a more reliable methodology for handling data.
With that regular process not in place, and with increasingly more users visiting our service, our database continued to grow at an accellerating pace. On June 3rd we started receiving automated emails from XWiki's infrastructure services that we were down to 20% of our disk space. We had been meaning to handle this problem for some time but with 33 emails arriving in our inboxes each day we finally decided to prioritize it.
Replaced the race condition (June 6th)
After the Xenops release we noticed an error that was occurring in our browser consoles fairly regularly and decided to debug it. We tracked it down and fixed it, but since we weren't looking for the other race condition described above, we managed to change the code in such a way that a functionally identical race condition was still present. We fixed one issue, but pads still weren't being pinned reliably.
Incorrect data archival (June 13th)
Having proceeded with fixing a variety of other bugs, I turned my attention back to solving our storage issue. Deleting data hadn't become any less scary than it had always been so I proceeded with caution, implementing an archival system that would move inactive data to what we termed "cold storage" for a set period before removing it permanently.
I implemented some code for iterating over our complete database and used that to create a script for checking the most recent modifications to user data. I read through it a number of times, tested it on my local database and had my colleague review it and test it on his machine. Before using it on our production database I made sure to also write and test a script that would restore archived files in case anything went wrong.
I think I must have sat in front of my laptop and stared at my screen for between five and ten minutes before I hit enter on the command to run the script. I had the code for the script on another monitor, and I double-checked it before deciding to proceed. I reloaded my drive to make sure everything was still there once it finished running, and it was. After twenty minutes or so of testing everything seemed alright, so I went on with my day.
Later on we finally noticed that there was a problem with one of our user accounts, specifically with a shared folder having disappeared. We stayed at the office late into the evening to figure out what had happened, and ended up tracking the problem to the pinning logic before deciding to follow up on it in the morning.
Final debugging and restoration (June 14th)
With as restful a night as I could manage under the circumstances, I came back to the office this morning with a bit of perspective on the issue. I wrote up a pad which collected all the information we had into one place, identifying the circumstances under which we believed the problem could occur.
I reviewed the script which restored archived files, making sure that it would not overwrite any user data if utilized. My colleague implemented a fix for the race condition which contributed to the pinning issue, which I deployed as soon as I could review it.
After writing a few more scripts I was able to determine the number of shared folders which had been replaced with conflicting entries with the same identifiers (237). Knowing this number allowed me to determine how to handle the issue. If the number was significantly smaller it might have been easier to handle, but the order of magnitude is such that we'll have to figure out an automated way to deal with the issue or else spend the next few weeks responding to emails and manually recovering files.
With a better grasp on the situation and with some confidence that it wasn't the database processing scripts which were incorrect, I restored the archived files with the exception of those which conflicted with the production database.
Conclusion
If I've learned anything in my time working on CryptPad it's that I should appreciate the reasons why the majority of the software industry doesn't work with encrypted database as we do. Even on a good day it can be a harder job than it would otherwise be. On a day like today we end up having to reason with what the clientside code would have done under various circumstances and think about what information we can access.
In any case, I'm very happy that we decided to turn off our deletion scripts months ago. Had they still been active, this relatively mild pinning and archival bug would have resulted in data loss.
While we can tell that 237 shared folders were affected, we still have to think about how the absence of that data would be handled by the code for user's CryptDrives. To further complicate things, we have to think beyond what our code would do and into what users might have done in reaction to what they saw. If they saw and removed the now-empty shared folders in their drive, they no longer have the encryption keys to decrypt them even though we've now restored the underlying data. Because we've spent so much time trying to protect our users' privacy we can't actually ascertain if they've interacted with this part of their drive at all.
On one hand, it makes my life that much more stressful to have to figure out the answers to these problems. On the other, I'm hopeful that by doing this work now I'll help pave the way for more developers to create services which offer similar protection for their users' data.
As stated above, if this particular mistake affected you, don't hesitate to contact us. Otherwise, I can only hope that the way we handle it ensures that you continue to trust us with your data.
Links