March 2024 status
Spring 2024 release (2024.3.0)
Spring 2024 release (2024.3.0)
🇫🇷 Post in French - Nous vous présentons dans quels scénarios CryptPad est sécurisé, et partageons des idées d'actions concrètes pour un usage de CryptPad respectant votre confidentialité.
We show you in which scenario CryptPad is secure, and give you ideas for concrete actions for a safe CryptPad usage.
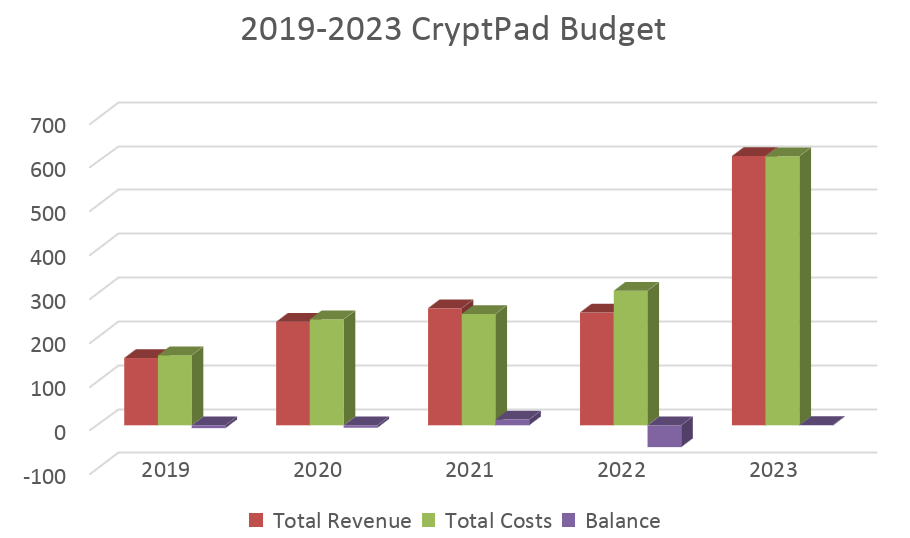
A summary of our budget for the year 2023 and planning for 2024
5.7 Documentation, Le Monde using CryptPad, FOSDEM recap, Post-mortems for recent CryptPad.fr outages


Links